Python利用哈希值比较两个文件的一致性
Python的内置函数hash(),深入发现通过python的哈希值可以做很多的事情
实现原理
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
加密散列函数,是散列函数的一种。它被认为是一种单向函数,也就是说极其难以由散列函数输出的結果,回推输入的资料是什么。这样的单向函数被称为“现代密码学的驮马”。这种散列函数的输入资料,通常被称为讯息(message),而它的输出结果,经常被称为讯息摘要(message digest)或摘要(digest)。它的过程如下:
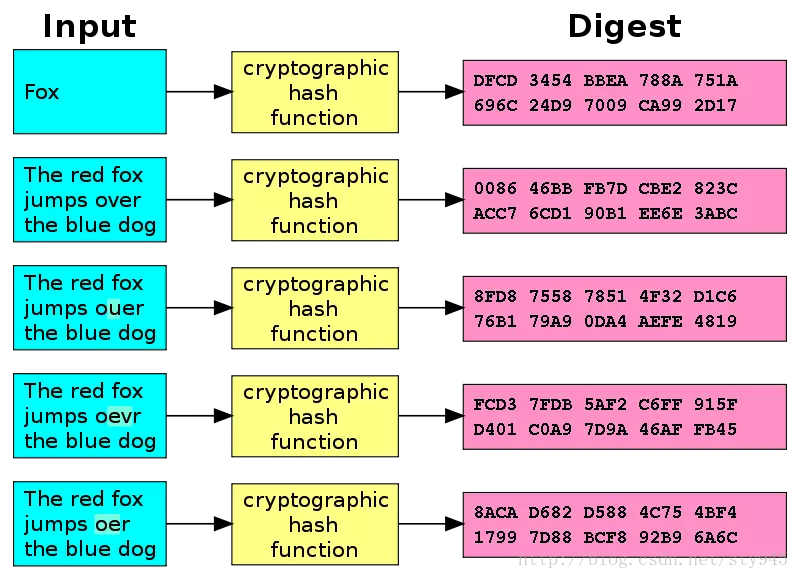
具体实现
MD5
MD5的全称是Message-Digest Algorithm 5(信息-摘要算法)。128位长度。目前MD5是一种不可逆算法。具有很高的安全性。它对应任何字符串都可以加密成一段唯一的固定长度的代码。
SHA1
SHA1的全称是Secure Hash Algorithm(安全哈希算法) 。SHA1基于MD5,加密后的数据长度更长,它对长度小于264的输入,产生长度为160bit的散列值。比MD5多32位。
因此,比MD5更加安全,但SHA1的运算速度就比MD5要慢了。
我们将演示使用MD5散列算法来hash文件。 我们不会一次性提取全部文件数据,因为一些文件非常大,会很消耗内存甚至一次性放不下。将文件分割成小块读取将使处理过程高效地使用内存。
在Python中内置的 hashlib 模块就包括了 md5 和 sha1 算法。而且使用起来也极为方便,我们使用md5算法来实现我们比较文件一致性的功能,我们会使用update()方法来对这个对象填充任意的字符串。在任何时候你都可以使用digest()或hexdigest()方法问它要目前为止填充的字符串的摘要。我们需要了解以下几个函数:
hash.update(arg)
hash.digest()
hash.hexdigest()
1 | # !/usr/bin/env python |
在代码中,我们通过将两段字符串txt1,txt2来模拟文件的改动,分别写入1.txt,2.txt,然后我们将两个文件分别读取,计算它们的MD5值,通过比较MD5值便可以知道它们是否一致。
需要注意:
1.是文件打开方式一定要是二进制方式,既打开文件时使用b模式,否则Hash计算是基于文本的那将得到错误的文件Hash,如果不用’rb’去读的话,而用’r’去读的话,我们读取的是uncode的编码,然后我们将读取到的内容编码成’utf-8’,即encode(‘utf-8’),然后进行MD5计算也是可以的。
2.为了避免读入的文件过大,我们是分块读取的。